December 2, 2025
Introducing the Alloy Architecture
A new foundational model for structured, incremental, declarative data engineering.
Today, DataForge is excited to introduce the Alloy Architecture, the most significant upgrade to our platform since we first launched. Alloy represents a reengineered foundation for how data pipelines are structured, executed, and refined - addressing long-standing challenges with hidden layers, unpredictable performance, and inconsistent transformation patterns.
For years, data teams have been asked to deliver reliable, governed, high-quality data products using architectural patterns that look clean in diagrams but break apart in practice. Medallion-style models are often framed as three simple layers: Bronze, Silver, Gold - but real pipelines contain dozens or even hundreds of hidden transformation stages buried inside:
- Common Table Expressions
- Temp tables
- dbt models and sub-models
- Spark/Dataset transformations
- User-defined staging tables
- Ad-hoc orchestration logic
These implicit layers introduce operational risk, slow down teams, and make it nearly impossible to achieve end-to-end lineage or enforce consistent transformation logic across domains.
The Alloy Architecture solves this problem by introducing a structured, statically defined processing flow that eliminates hidden layers entirely.
A Five-Layer Refinement Model - Designed for Clarity and Consistency
At the heart of Alloy is a deterministic refinement sequence:
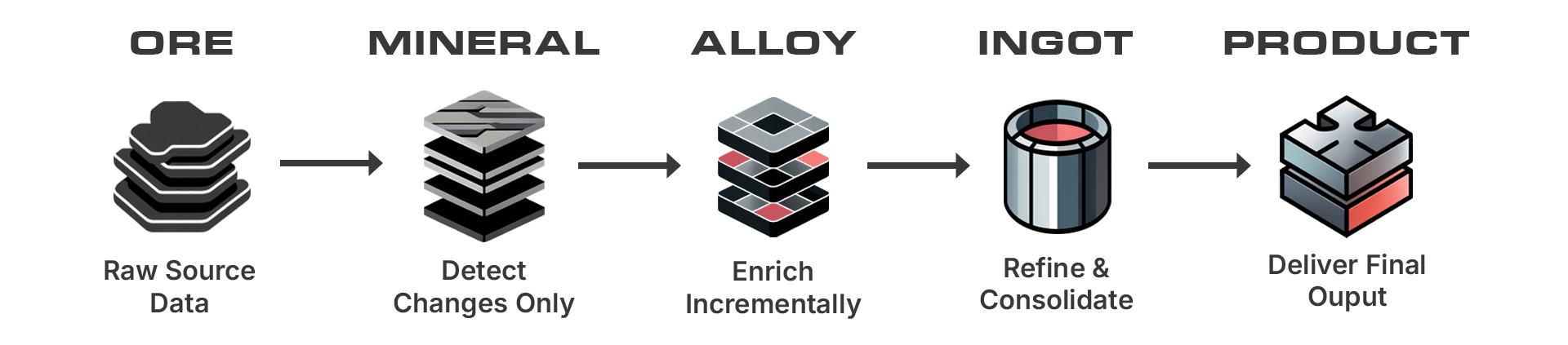
Each stage has one clear purpose, and every pipeline follows the same structured flow.
ORE
Unrefined data captured exactly as delivered from the source.
MINERAL
Purpose-built change detection isolates only the new or updated records.
ALLOY
Business logic, joins, and enrichment are applied only to the incremental batch - improving both performance and predictability.
INGOT
The enriched batch is merged into the full dataset through a consistent refinement process that ensures clean, canonical results.
PRODUCT
Final data outputs are materialized for analytics, operational systems, and downstream consumers.
This architecture makes the refinement process explicit, stable, and uniformly repeatable across every domain and every data source.
Incremental Processing - Built In, Not Bolted On
Traditional data engineering frameworks treat incremental loads as an optimization problem left to developers:
- Custom merge logic
- Timestamp parsing
- Soft/hard delete handling
- State tracking tables
- Conditional pipeline branches
- Fragile assumptions buried in code
This approach creates unnecessary variability and technical risk across domains.
Alloy takes a fundamentally different approach.
Incremental behavior is architecturally enforced, not optional. MINERAL and ALLOY are designed to process only new or updated data, while INGOT performs the structured, full-dataset refinement.
This design provides:
- Predictable scaling
- No per-table incremental logic
- Consistent change handling
- Simplified failure recovery
- Less custom code and fewer edge-case rules
Incrementalism isn’t an optimization. It’s a first-class architectural principle of Alloy.
Modernizing the Foundation - A Major Upgrade from DataForge’s Legacy Architecture
Prior versions of DataForge used a file-based refinement model, generating RAW, CDC, ENR, and HUB datasets as files in cloud storage. This approach enabled rapid early adoption but introduced challenges around:
- Navigability
- Governance and metadata consistency
- Managing partition evolution
- Cross-layer relationships
- Efficient incremental processing patterns
- Integration with native lakehouse governance tools
Alloy modernizes this foundation by transitioning the entire refinement flow to a fully table-native architecture.
This upgrade improves:
- Layer-to-layer transparency
- Debugging and troubleshooting
- Partitioning strategy consistency
- Observability across the refinement process
- Incremental execution reliability
- Cross-domain structural alignment
This modernization is a major upgrade for DataForge customers and represents a generational shift in how the platform models and processes data.
How Alloy Relates to Medallion
The Medallion Architecture is intentionally broad and flexible, which is why it has been widely adopted across the industry. Its three-tier model (Bronze, Silver, Gold) can describe a wide range of pipeline patterns depending on how teams choose to implement it.
The Alloy Architecture is something different.
While Alloy can conceptually map to Medallion, it introduces:
- Explicit, enforceable refinement stages
- A deterministic sequence without hidden layers
- Incremental processing built directly into the architecture
- A uniform pattern that applies consistently across domains
Alloy is not a simple interpretation of Medallion, it is an evolution.
It is a new architectural model designed to solve a different set of problems: reducing hidden complexity, improving consistency, and enabling predictable, declarative data engineering.
We will publish a dedicated follow-on article that provides a deeper comparison between Alloy and Medallion, including where they align and where they meaningfully diverge.
Why Alloy Matters
1. No More Hidden Layers
A static, five-step process replaces scattered logical operations inside notebooks, CTEs, or ephemeral tables.
2. Predictable Performance from Structural Incrementalism
Incremental behavior is part of the architecture itself - not a pattern left to individual developers.
3. Consistency Across Every Pipeline
Each source, domain, and transformation path follows the same refinement model.
4. Better Governance and Debugging
Structured refinement produces cleaner, more discoverable lineage and easier troubleshooting.
5. A Foundation for Declarative Transformation
Less code. More structure. More repeatability. More resilience.
The Beginning of a New Chapter
The Alloy Architecture brings structure to what was previously ambiguous, simplicity to what was previously fragmented, and determinism to what was previously unpredictable.
This release marks a major milestone for DataForge - and the foundation for everything that comes next.
More updates later this week.
Ready to try DataForge?
Start with the Community plan — free forever — or talk to our team.