December 4, 2025
Introducing Ember: A Structured Data Catalog for Declarative Pipelines
Discover how Ember's structured data catalog defines refinement rules and powers the Alloy five-layer architecture.
Earlier this week, we introduced the Alloy Architecture - a new, structured refinement model designed to eliminate hidden layers and bring predictability to data engineering.
Today, we’re excited to introduce the system that makes Alloy possible:
Ember is DataForge’s structured data catalog and declarative metadata engine.
Ember is more than a catalog of tables and fields. It is the definition layer that tells Alloy exactly how each step of the refinement process should behave.
Where Alloy provides the architectural flow, Ember provides the detailed instructions that drive it - clearly, consistently, and without ambiguity.
Why Ember Is Different From Traditional Data Catalogs
Most data catalogs work the same way: They scan SQL, code, notebooks, or dbt models to infer what pipelines are doing and attempt to document them after the fact.
This creates challenges most data teams know well:
- Hidden logic scattered across CTEs, temp tables, scripts, and models
- Catalogs drifting out of sync as code evolves
- Lineage that describes what happened, not what should happen
- Difficulty enforcing consistency across domains
- Metadata that reflects intentions rather than guarantees
Ember is designed for the opposite model.
Instead of scanning pipelines, Ember stores the rules that create them.
It doesn’t observe developer logic. It defines it — up front, in a structured, relational model.
This shift from descriptive to prescriptive metadata is what makes Ember fundamentally different from observability tools and traditional catalogs.
Ember as a New Kind of Data Catalog
Ember replaces the traditional “after-the-fact” catalog with a catalog that defines behavior, not just documentation.
Ember is:
- A structured data catalog
- A metadata engine
- A definition layer for transformation rules
- A control plane for the Alloy Architecture
- A single source of truth for how data should be refined
It bridges the familiarity of a catalog with the precision of a declarative execution model.
This makes Ember both recognizable and entirely new.
What Ember Stores and Manages
Ember contains a set of metadata objects that describe:
- What each data source looks like
- How new and changed records should be detected
- How attributes relate to one another
- What validation or quality rules apply
- Which enrichment steps should occur
- How data should be merged and refined
- What outputs should be produced for downstream systems
Each object has a well-defined purpose. Each relationship is encoded explicitly. Each rule is unambiguous.
Ember becomes the source of truth for how data is processed end-to-end — without relying on handwritten pipeline code or scattered configuration files.
How Ember Enables Alloy’s “No Hidden Layers” Approach

A major benefit of the Alloy Architecture is that it eliminates the hidden intermediate layers typically found in notebooks, models, and procedural pipelines.
This is only possible because Ember defines transformation behavior in a way that:
- Keeps related logic together rather than spreading it across tables
- Stores rules at the attribute level instead of burying them inside CTE chains
- Separates incremental processing rules from full-dataset refinements
- Provides clear instructions for how to enrich and merge data
- Removes the need for ad-hoc staging tables and temporary constructs
In other words:
Ember centralizes transformation rules so that Alloy can execute them cleanly — without creating additional layers behind the scenes.
This is the foundation of Alloy’s predictability, and the core reason Ember needed to be invented.
Ember + Alloy: Definition + Execution
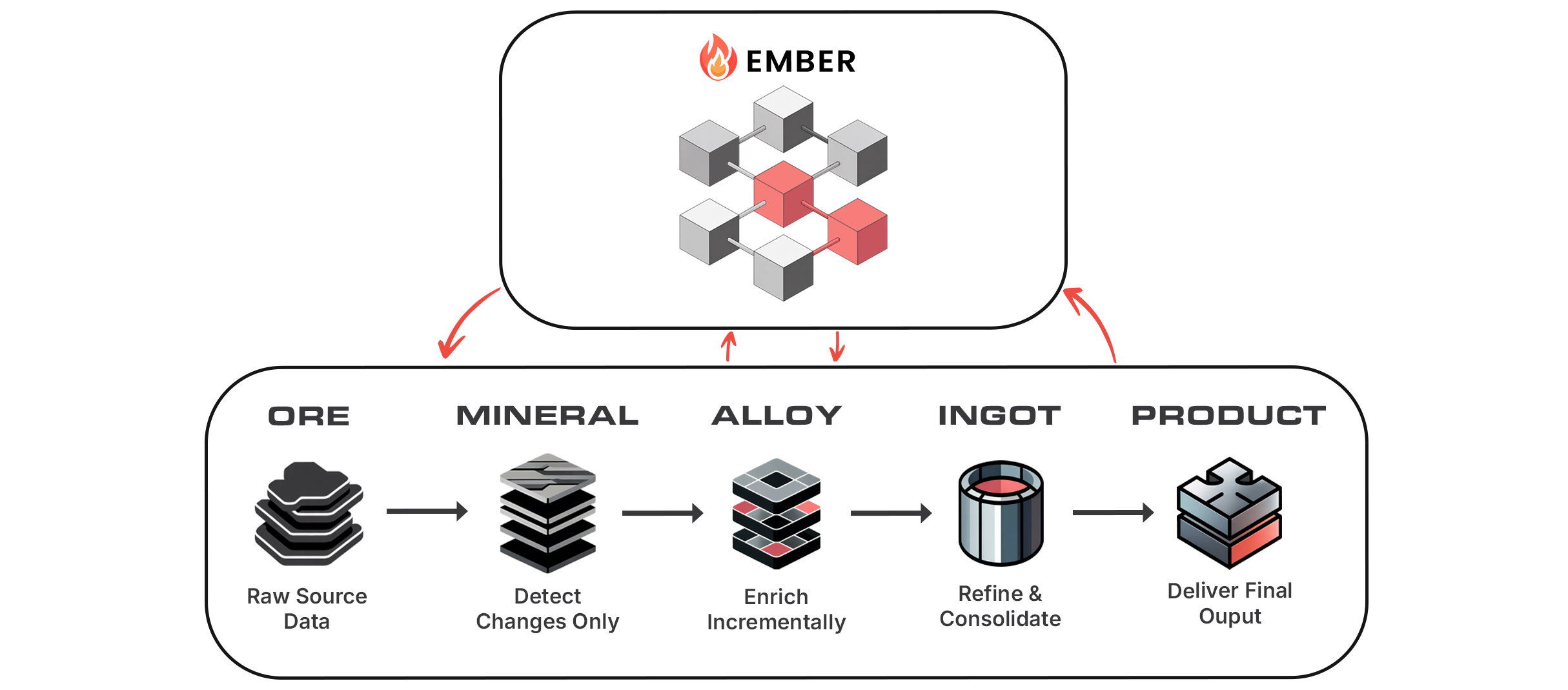
Alloy establishes a structured model for data refinement.
Ember provides the definitions that make that model consistent across every domain.
Together, they deliver:
- Clear, predictable refinement behavior
- Built-in incremental processing
- Uniform patterns across all sources
- Zero hidden layers or ad-hoc transformations
- Faster onboarding of new data domains
- Stronger governance and lineage
- A foundation for true declarative data engineering
This pairing represents a major step forward in how data pipelines can be modeled and executed.
What’s Coming Next
If you’d like to explore the foundations behind Ember and the Alloy Architecture, we’ve published two in-depth introductions:
- Introduction to the DataForge Declarative Transformation Framework https://www.dataforgelabs.com/blog/introduction-dataforge-framework
- Introduction to the DataForge Object Model https://www.dataforgelabs.com/blog/dataforge-intro-2
These articles provide background on the principles that guided the design of Ember’s metadata structures and Alloy’s refinement flow.
Next week, we’ll begin detailing the physical implementation of Alloy and Ember inside DataForge version 10.0 — starting with our Databricks experience early in the week, and concluding with a second major announcement on Thursday.
More to come soon.
Ready to try DataForge?
Start with the Community plan — free forever — or talk to our team.